The first native multimodal coding foundation model
New CogViT visual encoder + multimodal MTP; text-only code performance stays level with GLM-5-Turbo.
Overview
GLM-5V-Turbo was released on April 2, 2026 as Zhipu AI's first native multimodal coding foundation model. Zhipu describes it as "giving OpenClaw eyes." Unlike models that attach a visual encoder to a text model after the fact, GLM-5V-Turbo integrates vision during pretraining and then jointly optimizes multimodal and coding behavior after training.
Architecturally, it introduces a new CogViT visual encoder and an MTP (Multi-Token Prediction) structure compatible with multimodal input. It supports mixed image, video, file, and text input while keeping inference efficient. More than 30 reinforcement-learning tasks cover STEM, GUI agents, and video understanding.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 200,000 tokens (about 200K) |
| Max output | 128,000 tokens |
| Input modalities | Text, image, video, file |
| Output modalities | Text |
| Tools | streaming, JSON output, tool calls, Thinking / Non-Thinking, multimodal search, screenshots, web reading |
GLM-5V-Turbo adds native vision on top of GLM-5-Turbo without a visible drop in text-only code performance: CC-Backend 22.8, CC-Frontend 68.4, and CC-Repo-Exploration 72.2 are close to GLM-5-Turbo. See live pricing in the model catalog.
Benchmarks
The evaluation focus is multimodal coding, multimodal tool use, and GUI agents.
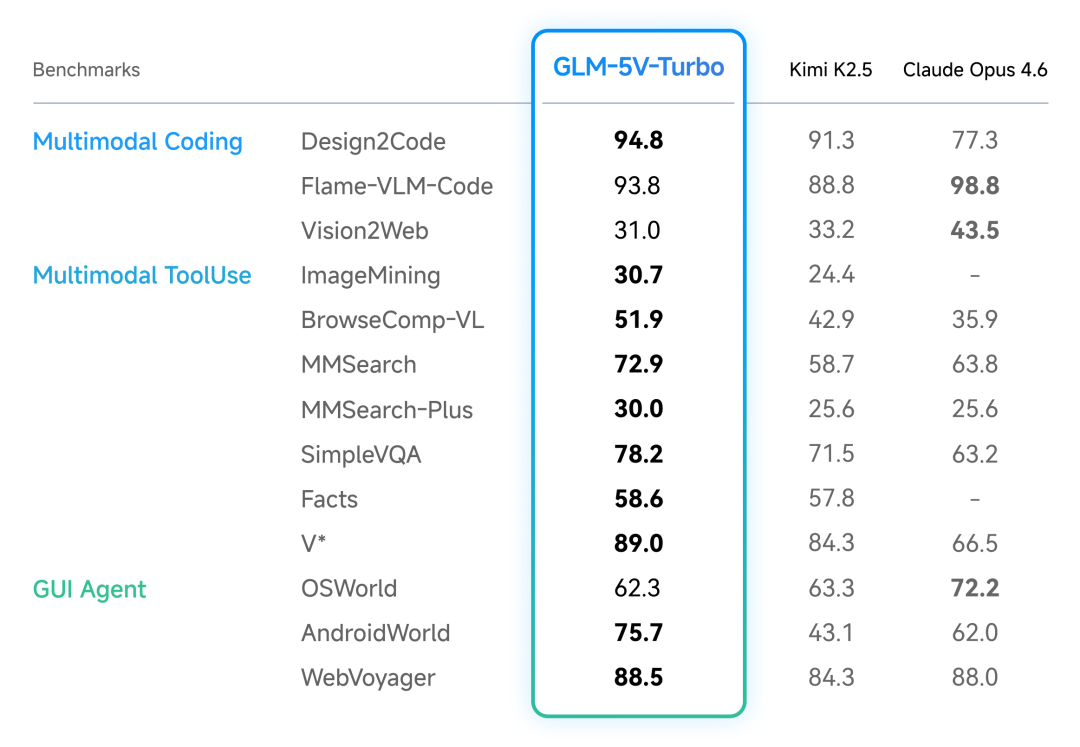
In multimodal coding, GLM-5V-Turbo scores Design2Code 94.8 and Flame-VLM-Code 93.8. In multimodal tool use, it leads on ImageMining 30.7, BrowseComp-VL 51.9, and MMSearch 72.9. GUI agent results include AndroidWorld 75.7 and WebVoyager 88.5.
Text-only code comparison
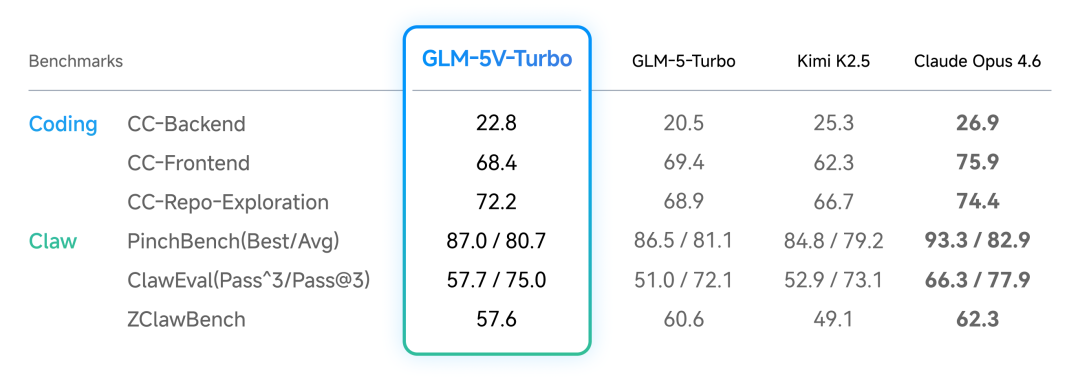
On CC-Bench-V2 and Claw scenarios, GLM-5V-Turbo stays close to GLM-5-Turbo, showing that the visual upgrade does not come at the cost of text code quality. Claude Opus 4.6 still leads on PinchBench Best and CC-Frontend, but GLM-5V-Turbo pulls ahead on multimodal fusion tasks such as BrowseComp-VL.
When to use it
- Screenshot or sketch to frontend code: Design2Code 94.8 makes it strong for UI reconstruction.
- Video-driven app reproduction: infer interface logic from recorded app interactions.
- GUI automation: AndroidWorld and WebVoyager scores support UI testing and web/mobile agents.
- Document intelligence: extract structured content from PDFs, screenshots, and charts.
- Multimodal research: combine image input, screenshots, and web reading in deep research tasks.
CrossModel exposes GLM-5V-Turbo through an OpenAI-compatible /v1/chat/completions API. Current pricing is available in the model catalog.