A flagship upgrade that works autonomously for 8+ hours
glm-5.1-highspeed delivers up to 400 tokens/s of API output.
Overview
GLM-5.1 is Zhipu AI's upgraded open flagship model released on April 7, 2026 under the MIT license. It has 754B total parameters and focuses on long autonomous work: Zhipu reports that GLM-5.1 can operate independently for more than 8 hours, planning, executing, debugging, and finishing engineering tasks without human intervention.
On SWE-Bench Pro, GLM-5.1 scores 58.4%, ahead of GPT-5.4 (57.7%), Claude Opus 4.6 (57.3%), and Qwen3.6-Plus (56.6%) in the cited ranking. Zhipu also released glm-5.1-highspeed, with API output up to 400 tokens/s.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 200,000 tokens (about 200K) |
| Max output | 128,000 tokens |
| Input modalities | Text |
| Output modalities | Text |
| Tools | streaming, JSON output, tool calls, Thinking / Non-Thinking |
Thinking mode spends internal reasoning before output and is better for deep planning; Non-Thinking mode is faster for lightweight chat and code completion. See live pricing in the model catalog.
Benchmarks
GLM-5.1's focus is agentic coding: solving real software issues inside repositories, not synthetic prompts.
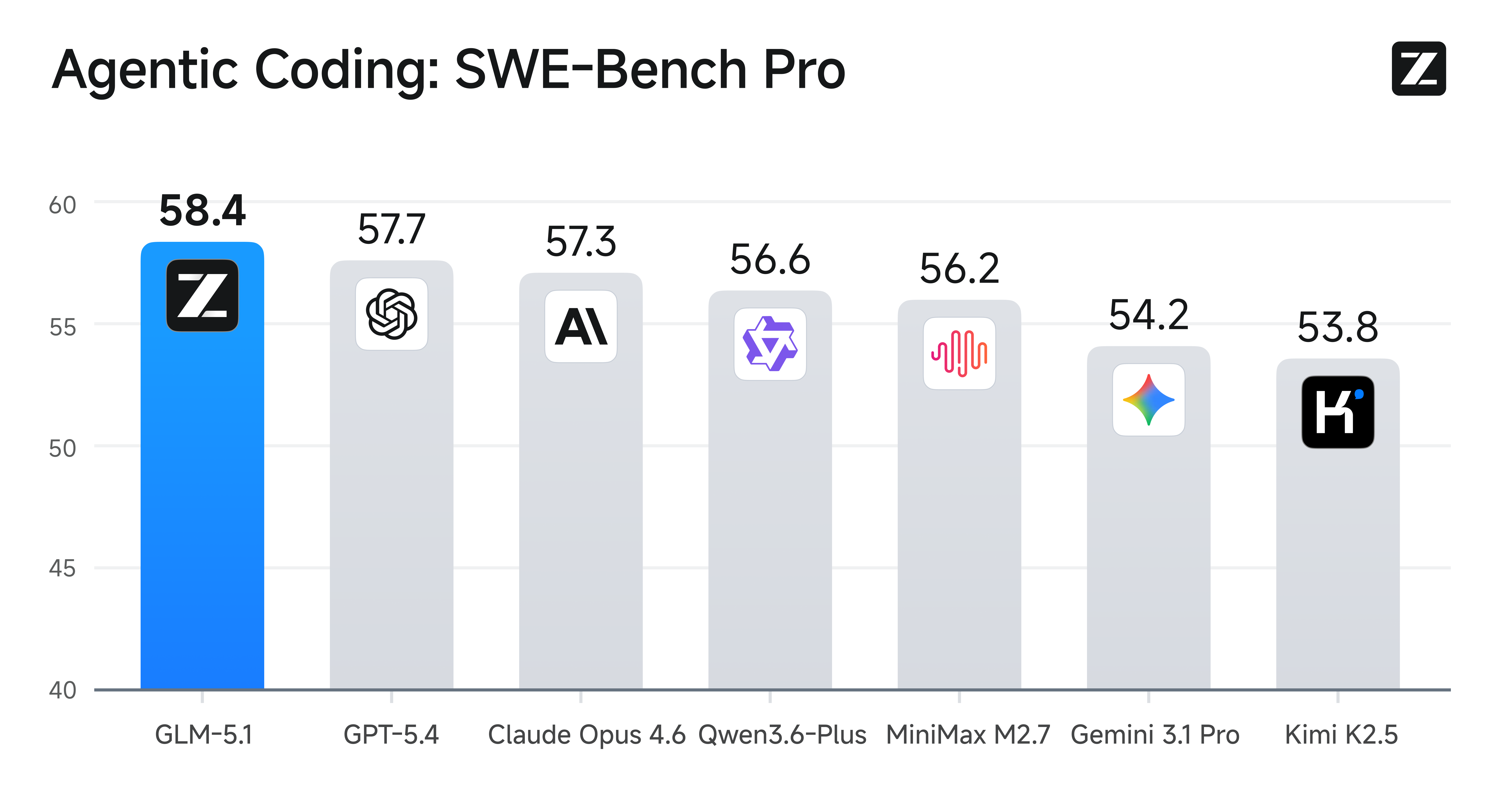
At 58.4% on SWE-Bench Pro, GLM-5.1 leads GPT-5.4 by 0.7 points and Claude Opus 4.6 by 1.1 points in the cited comparison.
Engineering optimization and long execution
Zhipu reports several long-running engineering cases:
An agent that runs for hours and finds its own bottlenecks
Real engineering cases from Zhipu, emphasizing autonomous iteration over one-turn generation.
- Vector database optimization: 655 iterations, raising query throughput from 3,108 QPS to 21,472 QPS, a 6.9x improvement.
- CUDA kernel optimization: 3.6x geometric mean speedup on KernelBench Level 3.
- Linux environment rebuild: completed a from-scratch runnable Linux environment within 8 hours.
- macOS UI reproduction: rebuilt a full macOS-style interface within 1 hour.
These examples are about sustained autonomous execution, bottleneck discovery, and switching technical approaches, not just one-turn code generation.
When to use it
- Long-horizon software engineering: multi-step plans, cross-file edits, and continuous debugging.
- Performance engineering: CUDA kernels, ML inference speedups, and system profiling.
- Autonomous DevOps: deployments, environments, dependency management, and operations flows.
- Realtime interaction: highspeed mode for coding assistants and latency-sensitive Q&A.
CrossModel exposes GLM-5.1 through an OpenAI-compatible /v1/chat/completions API. Current pricing is available in the model catalog.