From Vibe Coding to Agentic Engineering
Slime asynchronous agent-RL framework + sparse attention to lower inference cost under 200K context.
Overview
GLM-5 is Zhipu AI's open flagship model released on February 11, 2026 under the MIT license. Its theme is "from Vibe Coding to Agentic Engineering." The model uses a MoE architecture with 744B total parameters and 40B active parameters, expands pretraining data from GLM-4.7's 23T to 28.5T tokens, and introduces sparse attention to reduce long-context deployment cost.
At release, GLM-5 set an open-model record of 77.8% on SWE-bench Verified and led open models on Terminal Bench 2.0 with 56.2%. It also ranked first among open models on BrowseComp, MCP-Atlas, and tau^2-Bench, aligning its overall profile with Claude Opus 4.5 in Zhipu's comparisons.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 200,000 tokens (about 200K) |
| Max output | 128,000 tokens |
| Input modalities | Text |
| Output modalities | Text |
| Tools | streaming, JSON output, tool calls, Thinking / Non-Thinking |
GLM-5 uses the Slime asynchronous agent RL framework to improve long-horizon task execution, feeding real agent interactions back into training. Sparse attention lowers inference cost under 200K context. See live pricing in the model catalog.
Benchmarks
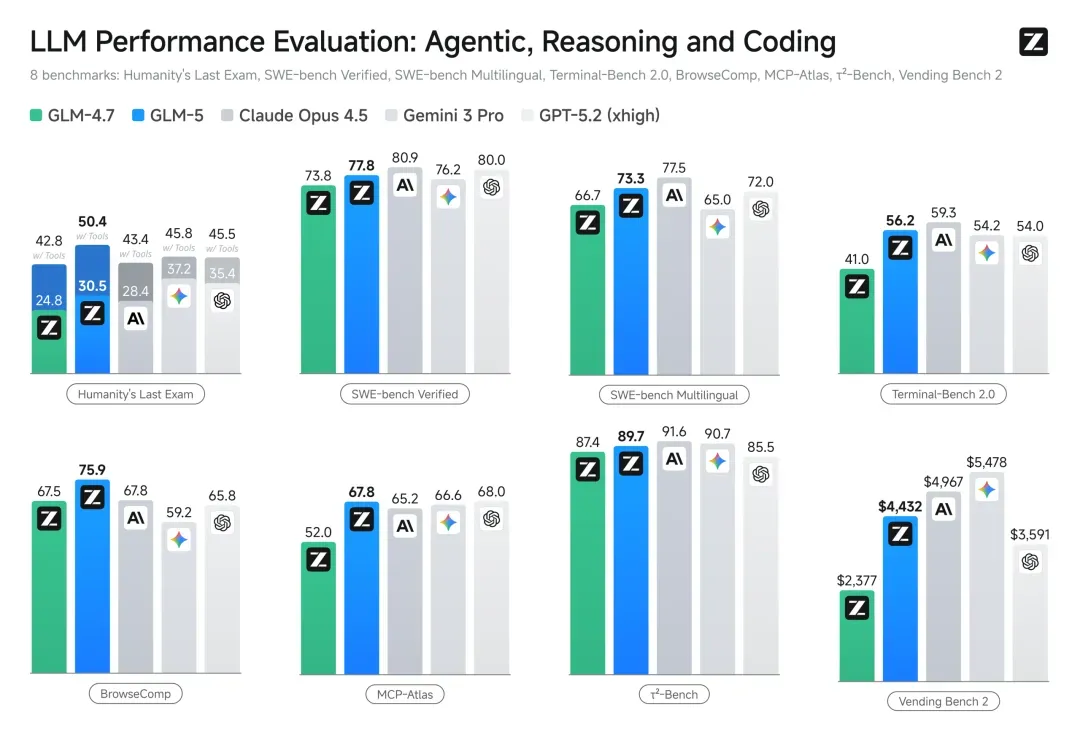
Against GLM-4.7, Claude Opus 4.5, Gemini 3 Pro, and GPT-5.2, GLM-5 leads open models on SWE-bench Verified (77.8), Terminal Bench 2.0 (56.2), and SWE-bench Multilingual (73.3). It also leads on BrowseComp (75.9) and MCP-Atlas (67.8).
Coding and terminal engineering

On CC-Bench-V2, GLM-5 exceeds Claude Opus 4.5 on frontend build success (98.0% vs 93.0%) and large-repo exploration (65.6% vs 64.5%), while backend end-to-end correctness is close (25.8% vs 26.9%).
Agent search and tools
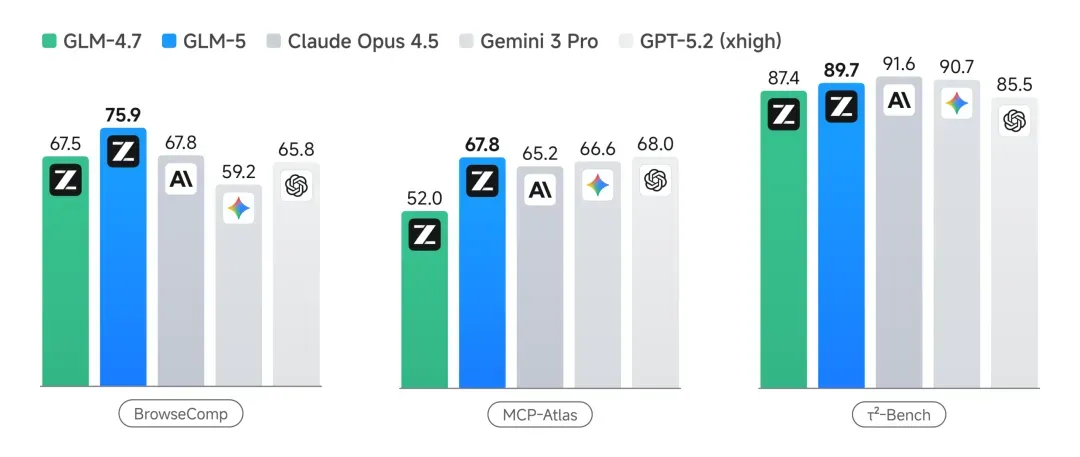
GLM-5 scores 75.9 on BrowseComp and 67.8 on MCP-Atlas, ahead of Claude Opus 4.5 in the cited comparison. Its 89.7 on tau^2-Bench is especially strong for phone-service style agent tasks.
Vending Bench 2
Vending Bench 2 simulates long-term business decisions. GLM-5 ends with $4,432, up from GLM-4.7 at $2,377 and close to Claude Opus 4.5 at $4,967.
When to use it
- End-to-end app development: requirements, implementation, tests, and deployment.
- General-purpose agents: search, tools, and cross-step state transfer.
- Documents and reports: long context plus tool calls for multi-source synthesis.
- Long-running decisions: business analysis, system tuning, and multi-step processing.
CrossModel exposes GLM-5 through an OpenAI-compatible /v1/chat/completions API. Current pricing is available in the model catalog.