The open flagship before the GLM-5 generation (MIT)
Fully evaluated on Huawei Ascend compute; introduces Interleaved / Preserved / Turn-level thinking.
Overview
GLM-4.7 is Zhipu AI's next-generation open flagship model, released on December 22, 2025 under the MIT license. It uses a MoE architecture with 355B total parameters and 32B active parameters, improving general chat, reasoning, and agent capabilities before the GLM-5 generation arrived.
In Code Arena, a large blind coding evaluation system, GLM-4.7 ranked first among open models and first among Chinese models. It also reached 95.7 on AIME 2025, an open-model SOTA in that comparison, and 73.8% on SWE-bench Verified, up 5.8 points over GLM-4.6. Zhipu also highlighted that the full test run used Huawei Ascend chips, making it a flagship model validated end-to-end on domestic compute.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 200,000 tokens (about 200K) |
| Max output | 128,000 tokens |
| Input modalities | Text |
| Output modalities | Text |
| Tools | streaming, JSON output, tool calls, three Thinking modes |
GLM-4.7 introduces Interleaved Thinking, Preserved Thinking, and Turn-level Thinking, giving agent frameworks more control over how reasoning is exposed, retained, and enabled per turn. See live pricing in the model catalog.
Benchmarks
GLM-4.7 covers reasoning, coding, and agent tasks, with official comparisons against GLM-4.6, DeepSeek-V3.2, Claude Sonnet 4.5, and GPT-5.1.
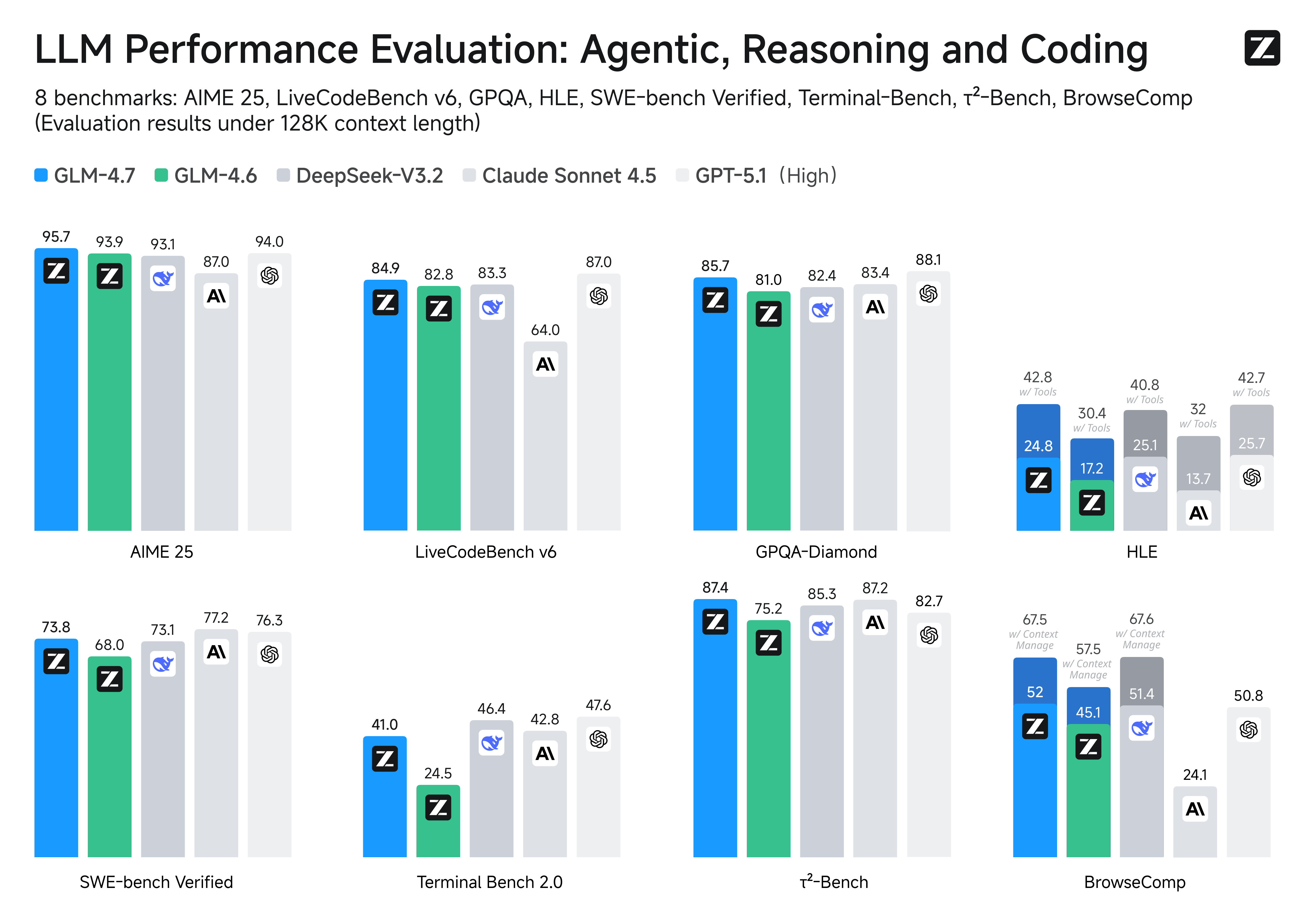
It reaches 95.7 on AIME 2025 and 97.1 on HMMT Feb. 2025. LiveCodeBench v6 is 84.9, placing it among frontier code models.
Coding and software engineering
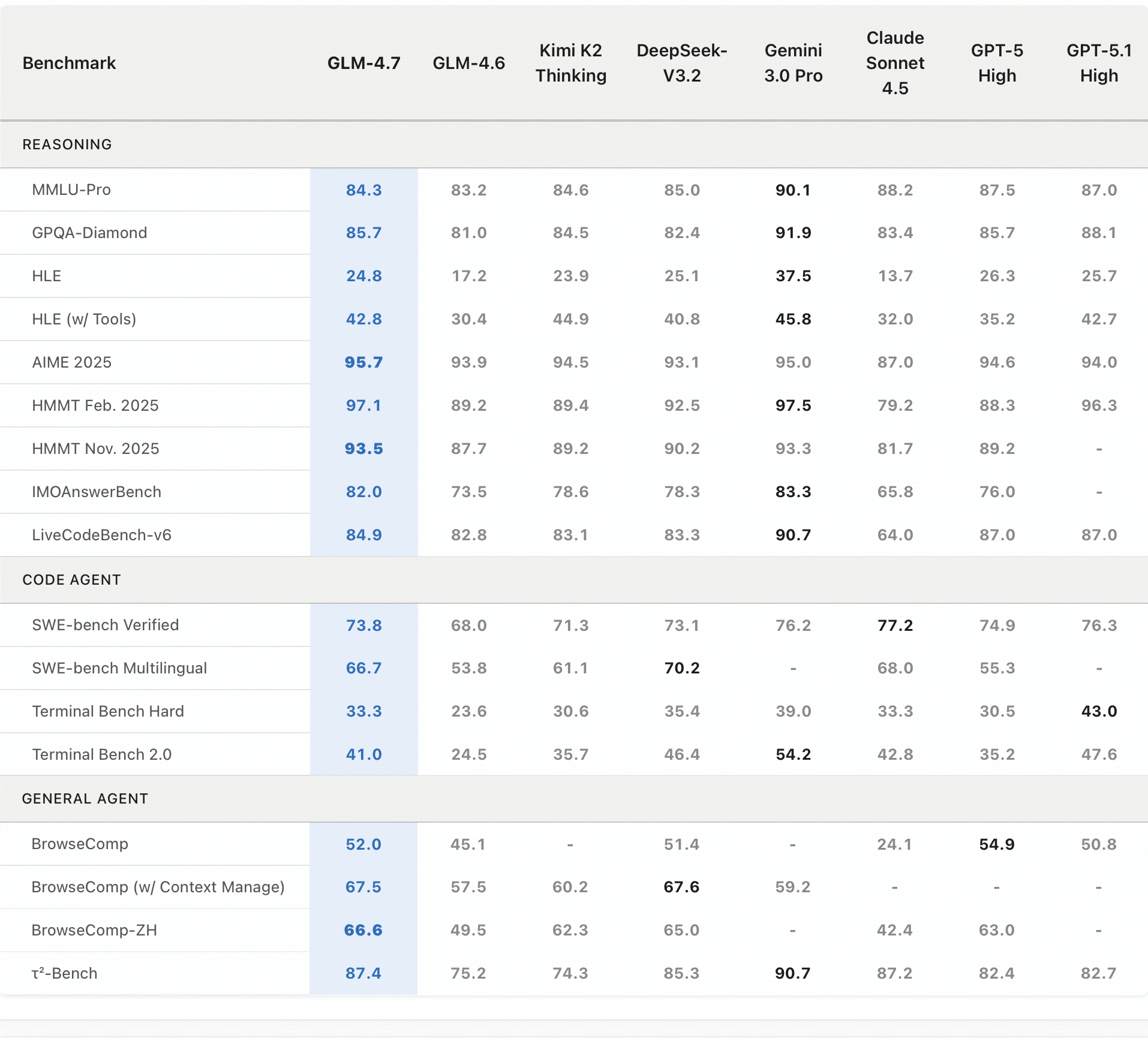
SWE-bench Verified is 73.8%, ahead of DeepSeek-V3.2 at 73.1% and Kimi K2 Thinking at 71.3%. SWE-bench Multilingual is 66.7%. Terminal Bench 2.0 reaches 41.0%, a large gain from GLM-4.6's 24.5%. HLE reaches 42.8%, the first GLM-4-family result above 40% on that extremely difficult general-reasoning benchmark.
Agent capability
BrowseComp is 52.0%, or 67.5% with context management, and tau^2-Bench is 87.4%, showing stronger multi-step execution and web-search behavior.
When to use it
- Coding assistants and code review: strong Code Arena and LiveCodeBench results.
- Math and science reasoning: AIME 2025 open SOTA in the cited comparison.
- Complex multi-turn agents: three Thinking modes for dynamic reasoning control.
- Domestic-compute environments: useful where supply-chain and deployment constraints matter.
CrossModel exposes GLM-4.7 through an OpenAI-compatible /v1/chat/completions API. Current pricing is available in the model catalog.