An open-source flagship for agents and coding
1.02T / 42B MoE + hybrid attention + 3-layer MTP, trained on 27T tokens in FP8, with native 1M context.
Overview
MiMo-V2.5-Pro is the flagship model released by Xiaomi's MiMo team in April 2026 and fully open-sourced under the MIT license, deeply optimized for complex agent and coding work. It is a leading open-source model on public leaderboards such as GDPVal-AA and ClawEval.
It uses a 1.02T total / 42B active MoE architecture (384 routed experts, top-8 per token) with hybrid attention: 10 global-attention layers + 60 sliding-window-attention layers (SWA:GA = 6:1, window 128), plus a learnable attention sink and a 3-layer MTP head. It was trained on 27T tokens in FP8 with native 1M token context.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Input modalities | Text |
| Output modalities | Text |
| Architecture | 1.02T total / 42B active MoE (384 experts, top-8) + hybrid attention + 3-layer MTP |
| Tools | function calling, JSON output, streaming, Thinking |
The team highlights token efficiency: at comparable scores, MiMo-V2.5-Pro uses about 40%–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 — a significant effect on the total cost of long-chain agent tasks. See current pricing in the model catalog.
Benchmarks
MiMo-V2.5-Pro's evaluation axis is agents and coding: the team compares it against DeepSeek V4 Pro, Kimi K2.6, GLM 5.1, Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6.
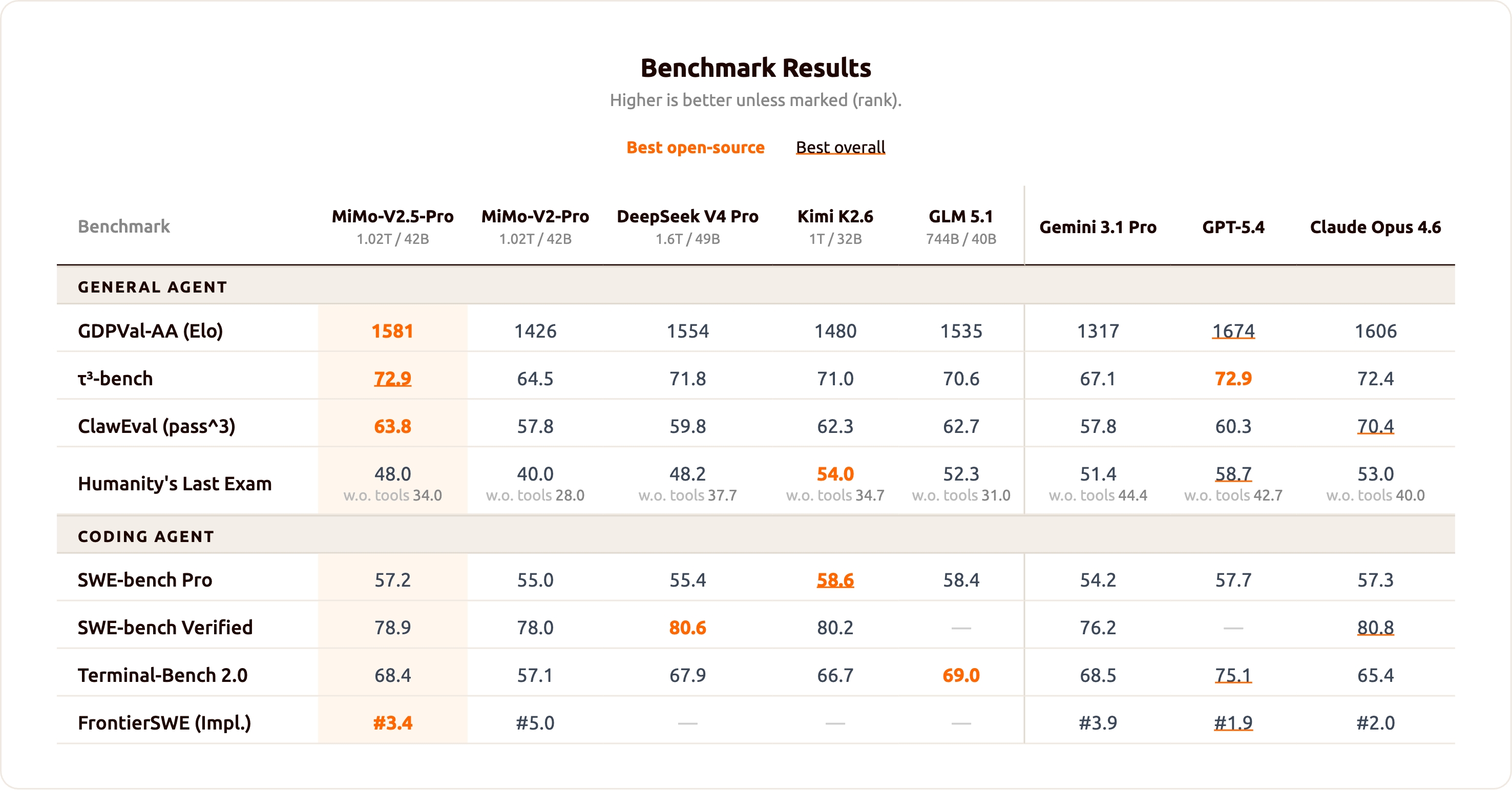
- General Agent: GDPVal-AA 1581 Elo (best open-source), τ³-bench 72.9, ClawEval (pass³) 63.8, Humanity's Last Exam 48.0
- Coding Agent: SWE-bench Verified 78.9%, SWE-bench Pro 57.2%, Terminal-Bench 2.0 68.4%, FrontierSWE rank #3.4
Terminal-Bench 2.0 leads Claude Opus 4.6 (65.4), SWE-bench Pro is within a point of Opus 4.6 and GPT-5.4, and the GDPVal-AA 1581 Elo is the highest among the open-source models in the group.
Long context
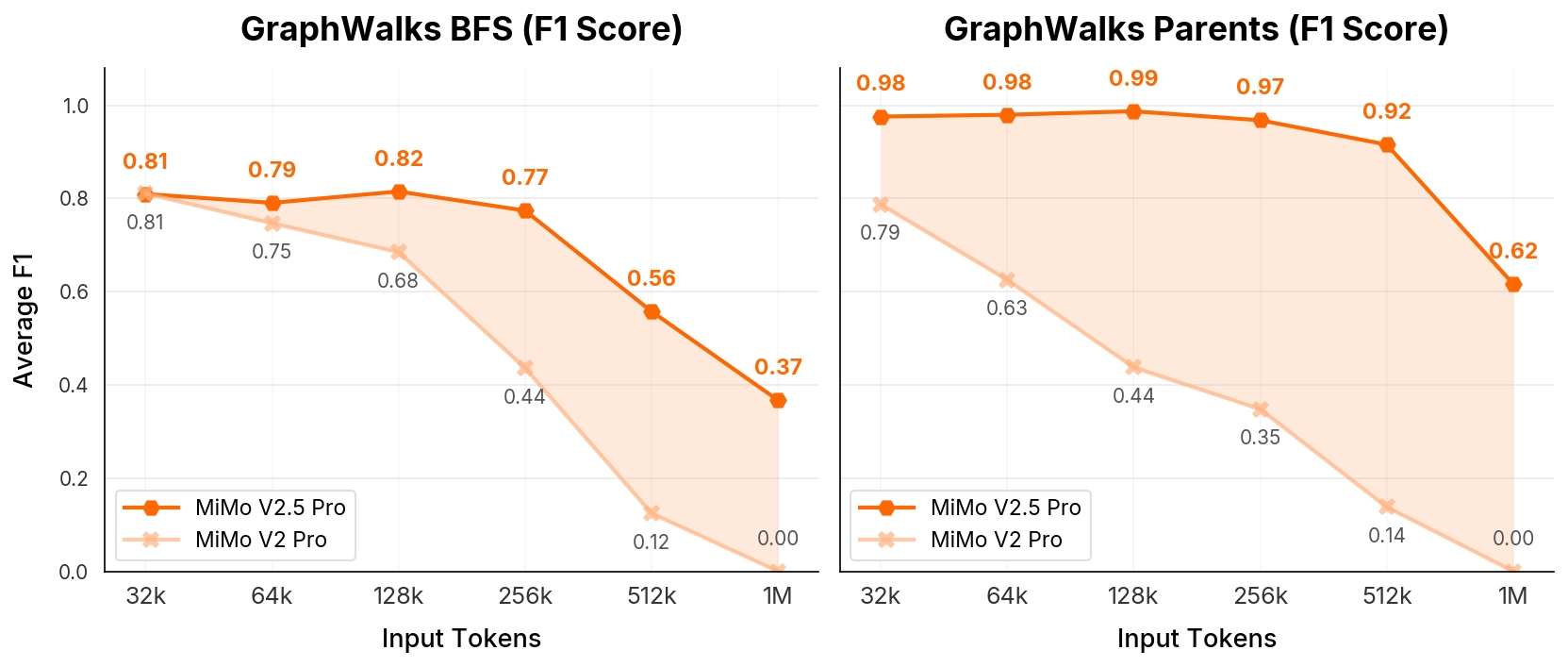
On GraphWalks, extending input to 1M tokens still holds BFS 0.37 / Parents 0.62 F1, while the previous V2-Pro dropped to 0.00 at 1M — a stark illustration of the hybrid-attention advantage at million-token scale.
Architecture
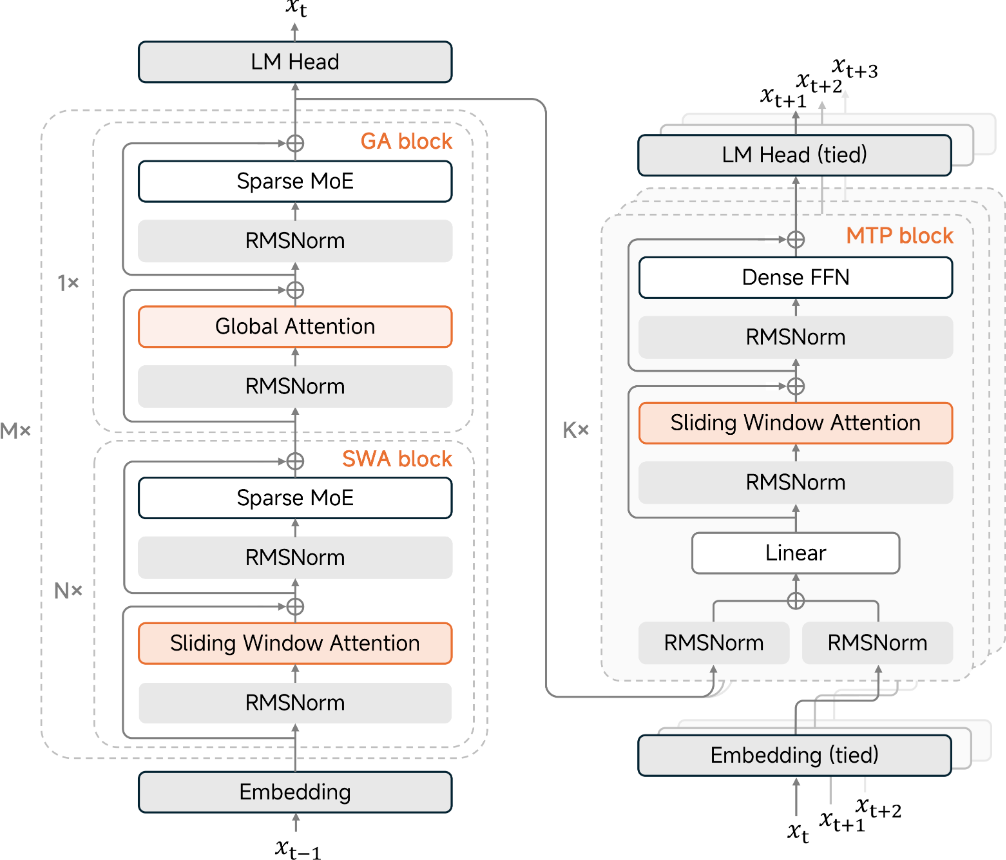
The alternating GA / SWA block design plus MTP lets the model preserve long-context ability while reducing inference memory and latency — the structural basis for running long-horizon agents at high token efficiency.
When to use it
- Autonomous coding agents: cross-file refactors and long-horizon software engineering, with SWE / Terminal scores close to closed-source flagships.
- Complex tool calling: high token efficiency keeps multi-turn, multi-tool agent flows cost-controlled.
- Long-context engineering: 1M context with stable long-range retrieval for large repos and multi-document synthesis.
- Local deployment: MIT license, commercial use and retraining allowed, with official SGLang / vLLM support.
CrossModel exposes MiMo-V2.5-Pro through both the OpenAI-compatible /v1/chat/completions and Anthropic-compatible /v1/messages APIs. Current pricing is available in the model catalog.