A natively omni-modal open-source agent model
The model natively supports text / image / audio / video; the CrossModel gateway currently exposes text and image input with text output.
Overview
MiMo-V2.5 is a natively omni-modal agent model open-sourced (MIT license) by Xiaomi's MiMo team in April 2026, alongside the flagship MiMo-V2.5-Pro. It unifies understanding of text, image, audio, and video in one model — a "single model for multimodality + agents" approach — with a 310B total / 15B active sparse MoE and a native 1M token context window.
Unlike approaches that bolt vision onto a text model, MiMo-V2.5's multimodality is trained natively, so its image and video scores do not come at the cost of its coding and agent abilities.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Input modalities | Text, image (model also natively supports audio / video) |
| Output modalities | Text |
| Architecture | 310B total / 15B active sparse MoE |
| Tools | function calling, JSON output, streaming, Thinking, vision |
The open-source model natively supports text / image / audio / video; the CrossModel gateway currently exposes text and image input with text output. See current pricing in the model catalog.
Benchmarks
MiMo-V2.5's evaluation axis is omni-modal coverage: lead on image and video understanding, hold coding and agent ability at a usable level for its size, and stay stable in million-token context.
Multimodal understanding
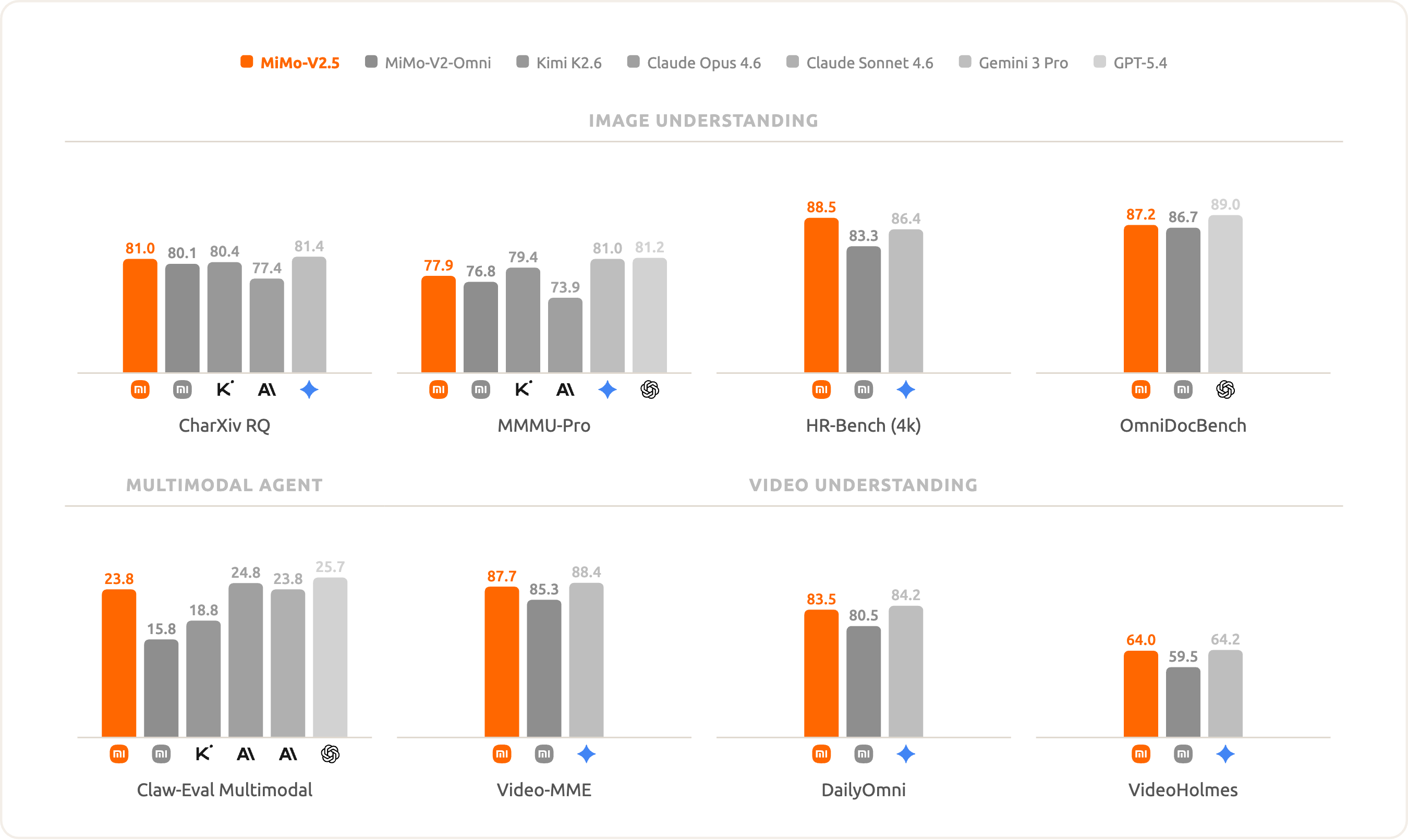
On image understanding, MiMo-V2.5 reaches HR-Bench 4k 88.5, OmniDocBench 87.2, MMMU-Pro 77.9, and CharXiv RQ 81.0, leading Claude Opus 4.6 / Sonnet 4.6 and Gemini 3 Pro on several metrics; on video it posts Video-MME 87.7, DailyOmni 83.5, and VideoHolmes 64.0. Omni-modal coverage is its biggest differentiator — one model handles text-image documents, charts, and long video.
Coding and agents
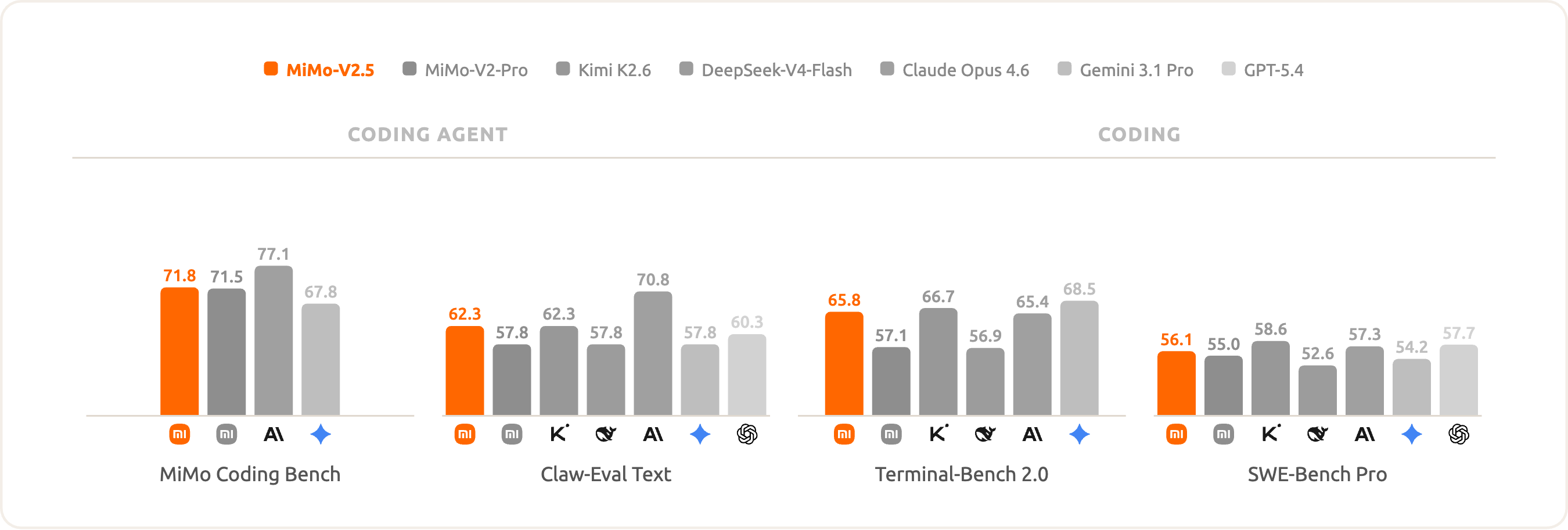
For a multimodal model, MiMo-V2.5's coding and agent ability is far from weak: MiMo Coding Bench 71.8, Claw-Eval Text 62.3, Terminal-Bench 2.0 65.8, and SWE-Bench Pro 56.1 — well-balanced for its size and enough to drive agent tasks in UI- and screenshot-bearing environments.
Long context
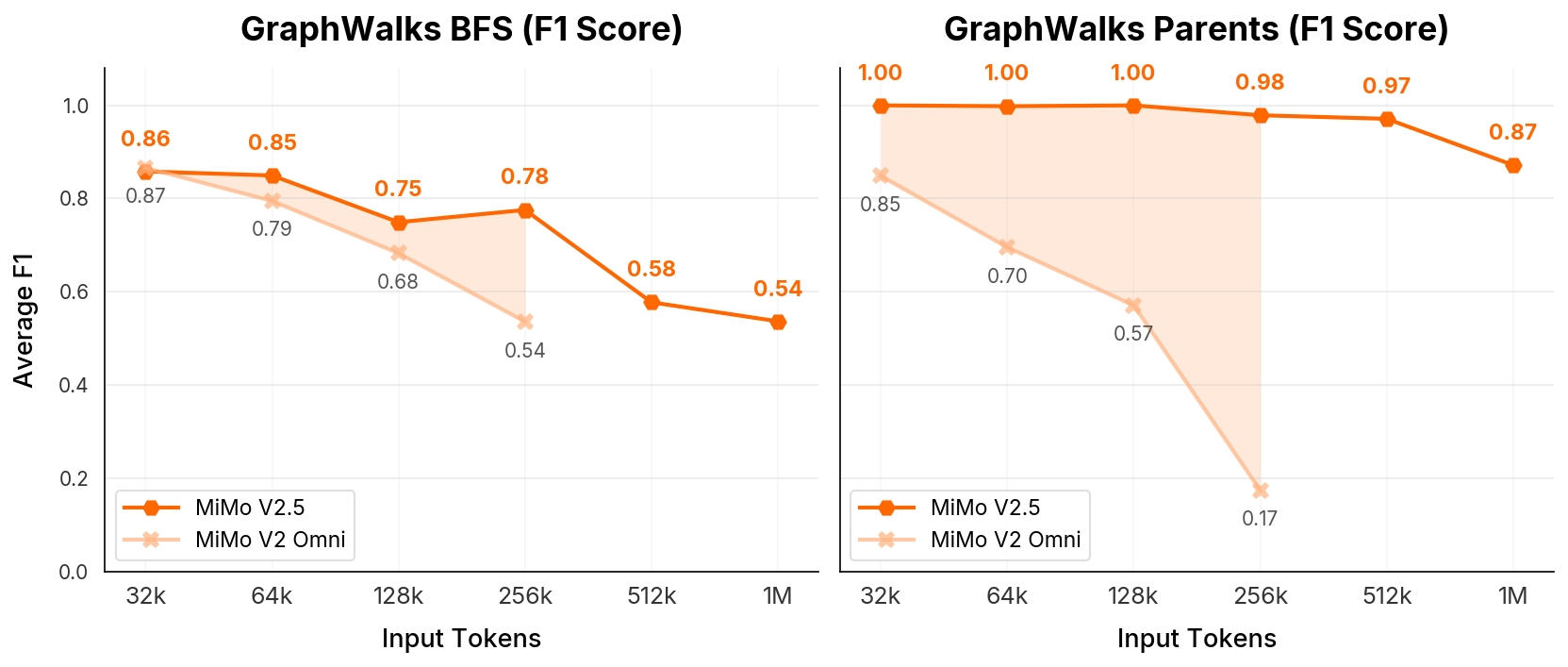
On GraphWalks, extending input to 1M tokens still holds BFS 0.54 / Parents 0.87 F1, while the previous V2-Omni degraded sharply at much shorter lengths — giving it a genuinely usable million-token multimodal context for retrieval over large source sets.
When to use it
- Multimodal understanding: mixed text-image documents, chart QA, long-video understanding and summarization.
- Multimodal agents: agent tasks executed in screenshot / UI environments.
- Long-context knowledge work: 1M context for retrieval and synthesis over large document and asset sets.
- Local deployment: MIT license, commercial use and retraining allowed, with official SGLang / vLLM support.
CrossModel exposes MiMo-V2.5 through both the OpenAI-compatible /v1/chat/completions and Anthropic-compatible /v1/messages APIs (text + image). Current pricing is available in the model catalog.