
Overview
DeepSeek V4 Pro is the flagship V4 Preview model released on April 24, 2026. DeepSeek lists it at 1.6T total / 49B active parameters with roughly 33T tokens of pre-training — an open-weight MoE positioned near top closed-source systems, with 1M context available as a default service capability rather than a costly premium setting.
Pro is the high-capability tier in the V4 family. It shares the same API surface and context capability as Flash; the difference is scale, stability headroom, and unit cost. Compared with Flash it is heavier and slower, but it keeps more margin for hard reasoning, complex code, long-horizon agents, knowledge-intensive analysis, and production tasks where the final answer needs to be more stable.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 65,000 tokens (CrossModel configuration) |
| Input modalities | Text |
| Output modalities | Text |
| Architecture | 1.6T total / 49B active MoE |
| Tools | streaming, JSON output, tool calls, Thinking / Non-Thinking |
DeepSeek supports both OpenAI Chat Completions and Anthropic-style formats. V4 Pro and Flash both support Thinking and Non-Thinking modes, plus JSON Output, Tool Calls, and Chat Prefix Completion. See live pricing and cache rules in the model catalog.
Pro vs Flash
A two-tier split inside the V4 family
Pro carries the high-value, hard tasks; most decomposable, verifiable steps start on Flash, with difficult samples escalated to Pro.
DeepSeek V4 Preview ships in two sizes: Pro at 1.6T / 49B active and Flash at 284B / 13B active. Pro is the better fit for agentic coding, knowledge, and Math/STEM/Coding reasoning; Flash trades some of that margin for faster and more economical API use. A common pattern is to make Flash the default entry point and reserve Pro for the few high-value, high-difficulty steps.
Benchmarks
DeepSeek compares V4 Pro Max against Claude Opus 4.6 Max, GPT-5.4 xHigh, Gemini 3.1 Pro High, and other high-end configurations, across both knowledge/reasoning and agentic capabilities.
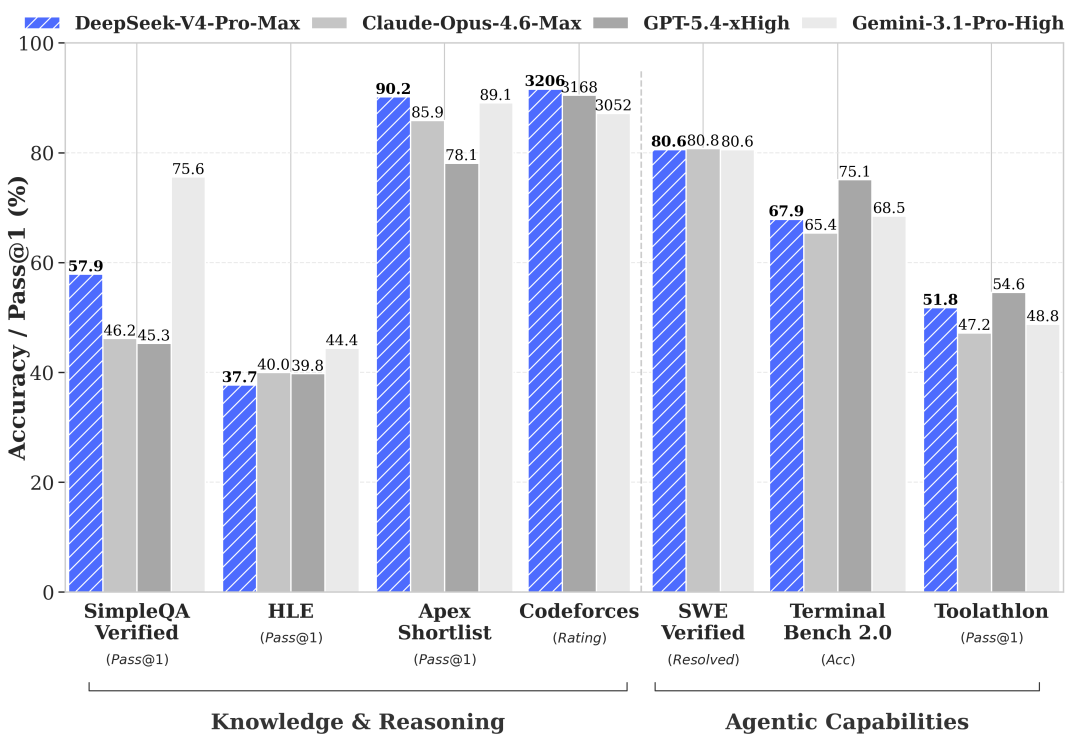
On the knowledge and reasoning side, V4 Pro Max posts Apex Shortlist 90.2, Codeforces 3206, and HLE 37.7; on SimpleQA Verified 57.9 it trails Gemini 3.1 Pro High but stays clearly ahead of GPT-5.4 xHigh and Claude Opus 4.6 Max. On the agentic side, SWE Verified 80.6, Terminal Bench 2.0 67.9, and Toolathlon 51.8 all sit near the top of the cited group. The Codeforces 3206 rating in particular shows its headroom on contest-level algorithmic problems.
Long context and architecture
Making 1M context a default capability
Token-wise compression and DSA together make million-token context a default path rather than a costly premium setting.
DeepSeek describes V4's architectural work around token-wise compression and DSA (DeepSeek Sparse Attention), with the goal of making 1M context a default path. For Pro, that matters most in large codebases, long documents, log analysis, and multi-turn agent traces where retrieval, reasoning, and tool use all need to stay aligned — and sparse attention plus compression are exactly what keep those long-range costs down.
When to use it
- Complex code and software engineering: cross-file repairs, test diagnosis, refactors, and SWE-style tasks.
- Hard reasoning: math, STEM, contest problems, and analyses that need verification.
- Enterprise agent workflows: browser, terminal, and tool-calling loops where stability matters.
- Long-context knowledge work: contracts, research material, large repos, and multi-document synthesis.
CrossModel exposes DeepSeek V4 Pro through an OpenAI-compatible /v1/chat/completions API. Current pricing is available in the model catalog.