Near-flagship quality at production latency and unit cost
Supports both Extended Thinking and Adaptive Thinking — the default choice for most online services.
Overview
Claude Sonnet 4.6 is Anthropic's balanced production model, released on February 17, 2026. It improves substantially over Sonnet 4.5 in coding, computer use, long-context reasoning, agent planning, and design work. In Claude Code tests, developers preferred Sonnet 4.6 around 70% of the time, and even preferred it over Opus 4.5 around 59% of the time.
It supports both Extended Thinking and Adaptive Thinking, which makes it the default choice for many production systems: close to flagship quality, lower latency than Opus, and more attractive unit economics for steady API traffic.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 65,536 tokens |
| Input modalities | Text, image |
| Output modalities | Text |
| Tools | function calling, structured outputs, streaming, computer use, MCP |
| Reasoning | Extended Thinking + Adaptive Thinking |
Prompt caching uses product-level multipliers: cache reads are 0.1x the base input rate, 5-minute writes are 1.25x, and 1-hour writes are 2x. See live pricing in the model catalog.
Benchmarks
What makes Sonnet 4.6 notable is how close it gets to flagship Opus 4.6 on coding and computer use, while actually overtaking it on knowledge-work ELO. Anthropic's comparison table places it alongside Opus 4.6, Opus 4.5, Gemini 3 Pro, and GPT-5.2.
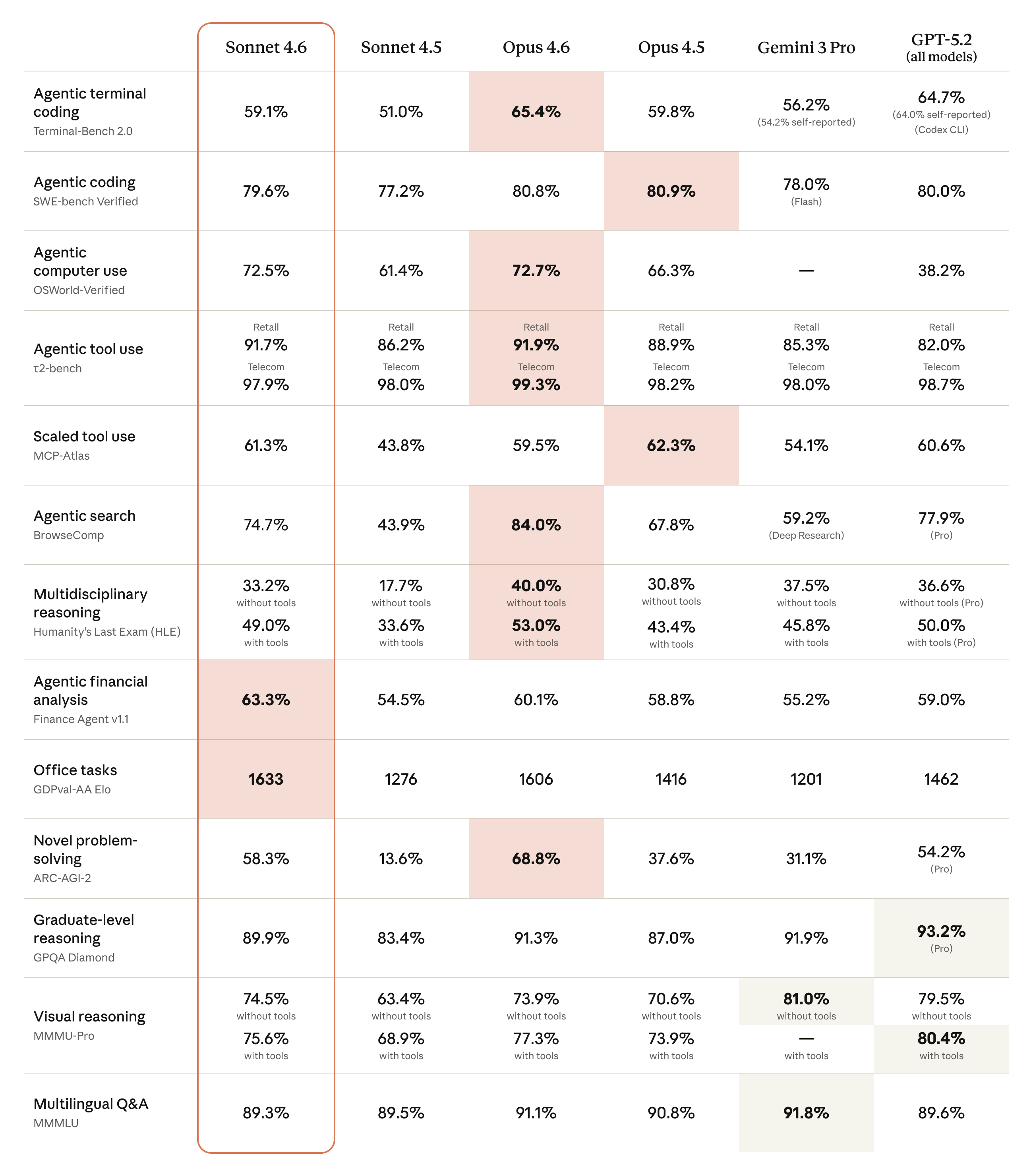
Coding and computer use
Coding and computer use approach flagship Opus 4.6
SWE-bench Verified nearly matches Opus 4.6; OSWorld ties Opus 4.6 and improves sharply over Sonnet 4.5.
On SWE-bench Verified, Sonnet 4.6 scores 79.6%, within a point of Opus 4.6's 80.8% and well ahead of Sonnet 4.5's 77.2%. OSWorld-Verified computer use reaches 72.5%, essentially tied with Opus 4.6 (72.7%) and a large jump over Sonnet 4.5 (61.4%). Terminal-Bench 2.0 climbs to 59.1% from 51.0%.
Knowledge work
Office ELO overtakes flagship; finance analysis improves sharply
GDPval-AA reflects reports, contracts, and research synthesis; Finance Agent v1.1 gains nearly 9 points over Sonnet 4.5.
Sonnet 4.6 posts 1633 ELO on GDPval-AA, ahead of Opus 4.6's 1606 — a Sonnet-tier model leading the office/knowledge-work comparison. Finance Agent v1.1 rises to 63.3% from Sonnet 4.5's 54.5%, and GPQA Diamond with tools reaches 89.9%, near flagship-level graduate reasoning.
When to use it
- Coding and software engineering: PR repair, code review, refactoring, and tests at near-Opus accuracy.
- Computer use and browser automation: UI actions and agent workflows where Opus latency is not necessary.
- Office and knowledge work: reports, document analysis, and data consolidation — where its GDPval-AA lead pays off.
- Production API services: lower latency than Opus for streaming chat and online inference.
Sonnet 4.6 vs Opus
Sonnet 4.6 is the right default for high-volume online traffic: it matches Opus 4.6 on most everyday coding and computer-use work at lower latency and cost. Reserve Opus 4.7 / 4.8 for the hardest reasoning, large-codebase changes, and long-horizon agents where peak accuracy justifies the premium.
CrossModel exposes Claude Sonnet 4.6 through Anthropic-compatible /v1/messages and OpenAI-compatible /v1/chat/completions. Current pricing is available in the model catalog.