
Overview
Claude Opus 4.8 is Anthropic's flagship model released on May 28, 2026. It builds on Opus 4.7 without changing the base price, and the two headline improvements are honesty and reasoning control. In agentic tasks, the chance that Opus 4.8 notices a code defect but fails to flag it is about one quarter of Opus 4.7's rate. It is also more willing to express uncertainty, with lower overall misaligned behavior.
Reasoning control also becomes more explicit: instead of only choosing a model/effort preset, developers can adjust Effort Control independently. Higher effort triggers deeper thinking more often, trading tokens for reliability.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Input modalities | Text, image |
| Output modalities | Text |
| Tools | function calling, structured outputs, streaming, computer use, MCP |
| Reasoning | Adaptive Thinking + independent Effort Control |
Effort Control adjusts reasoning depth independently from model selection. Fast mode outputs about 2.5x faster at roughly 2x the standard rate, while being about 2/3 cheaper than earlier fast modes. Prompt caching uses 0.1x cache reads, 1.25x 5-minute writes, and 2x 1-hour writes. See live pricing in the model catalog.
Benchmarks
Opus 4.8's benchmark story is agentic coding, knowledge work and computer use, and multidisciplinary reasoning. It leads its four-model comparison on SWE-Bench Pro (69.2%), Humanity's Last Exam with tools (57.9%), OSWorld-Verified (83.4%), GDPval-AA (1890 ELO), and Finance Agent v2 (53.9%).
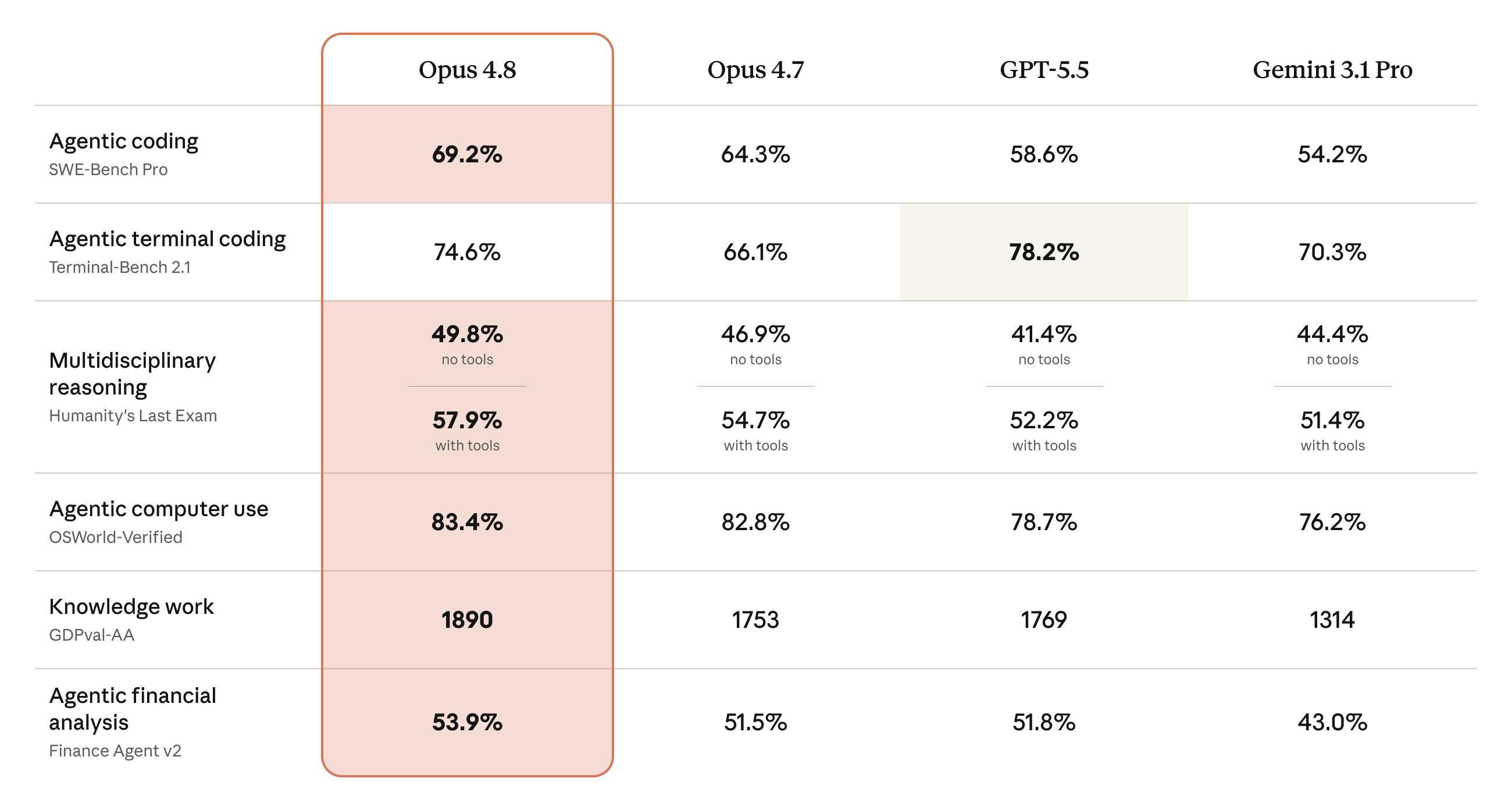
Agentic coding
Top-tier agentic coding, with Terminal-Bench up 8.5 points
SWE-Bench Pro and Terminal-Bench 2.1 simulate real engineering loops: inspect state, run tests, iterate, and repair.
SWE-Bench Pro measures planning, editing, and validation inside real GitHub issue environments. Opus 4.8 scores 69.2%, ahead of Opus 4.7 (64.3%) and GPT-5.5 (58.6%). On Terminal-Bench 2.1 it reaches 74.6%, up 8.5 points over Opus 4.7, with GPT-5.5 narrowly ahead at 78.2%.
Knowledge work and computer use
Leading comparison scores for knowledge work, computer use, and finance agents
GDPval-AA covers deliverable-heavy work such as reports, contracts, and research synthesis; OSWorld-Verified covers long desktop and browser workflows.
GDPval-AA reaches 1890 ELO, ahead of GPT-5.5 (1769), Opus 4.7 (1753), and Gemini 3.1 Pro (1314). OSWorld-Verified is 83.4%, covering long browser and desktop workflows.
Reasoning
Humanity's Last Exam: top comparison score with and without tools
HLE includes more than 3,000 expert-written questions across very hard domains such as math, physics, law, and medicine.
On Humanity's Last Exam, Opus 4.8 scores 49.8% without tools and 57.9% with tools, the highest in the comparison. The 8.1-point tool gain makes it a strong fit for search, code execution, and other tool-augmented reasoning chains.
When to use it
- Complex software engineering: cross-file changes, regression diagnosis, and agentic code review where missed defects are expensive.
- Long-running agents: MCP and computer-use workflows with strong execution reliability.
- Enterprise knowledge work: reports, contracts, research synthesis, and finance workflows.
- High-stakes reasoning: harder tasks where higher Effort Control is worth the tokens.
- Human-reviewed workflows: tasks where explicit uncertainty and fewer silent misses matter.
CrossModel exposes Claude Opus 4.8 through Anthropic-compatible /v1/messages and OpenAI-compatible /v1/chat/completions. Current pricing is available in the model catalog.