
Overview
Claude Opus 4.7 is Anthropic's flagship model released on April 16, 2026. It is the strongest generally available Claude version, improving over Opus 4.6 across agentic coding, graduate-level reasoning, visual understanding, and tool-augmented agents. It keeps the 1M-token context window of the 4.6 generation and adds a new tokenizer that can split the same text into up to 1.35x as many tokens, giving the model finer semantic granularity on dense inputs.
Opus 4.7 is aimed at the hardest tasks: long-running agent workflows, large-codebase changes, and research or document work that spans tools. It introduces an xhigh effort level on top of Adaptive Thinking, giving developers a more precise tradeoff between token spend and reasoning depth.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 131,072 tokens |
| Input modalities | Text, image (long edge up to 2,576 px, about 3.75 MP) |
| Output modalities | Text |
| Tools | function calling, structured outputs, streaming, computer use, MCP |
| Reasoning | Adaptive Thinking with low / medium / high / xhigh effort |
Prompt caching uses product-level multipliers: cache reads are 0.1x the base input rate, 5-minute writes are 1.25x, and 1-hour writes are 2x. See live pricing in the model catalog.
Benchmarks
Opus 4.7's evaluation story spans three axes: agentic coding, reasoning and vision, and tool-augmented agents. Anthropic's published comparison table puts Opus 4.7 ahead of Opus 4.6 on nearly every row, with the frontier "Mythos Preview" entry shown only as a forward-looking reference.
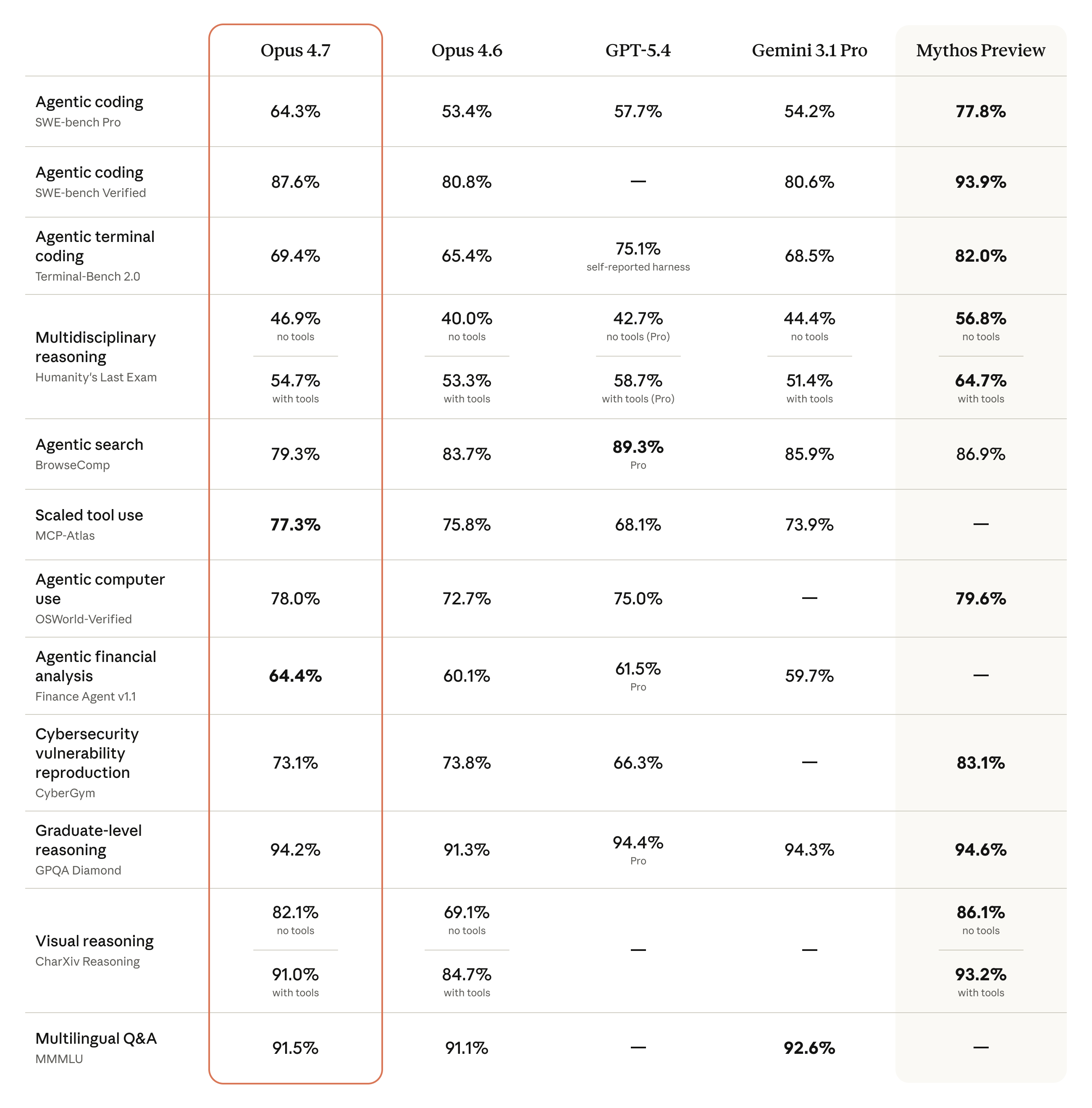
Agentic coding
Across-the-board gains over Opus 4.6 on real codebases
The SWE-bench suite repairs real GitHub issues; Terminal-Bench 2.0 targets terminal agent workflows.
On SWE-bench Verified, Opus 4.7 reaches 87.6%, up from Opus 4.6's 80.8%, and on the harder SWE-bench Pro it scores 64.3% versus 53.4%. Terminal-Bench 2.0 rises to 69.4% (from 65.4%), confirming that the gains hold in real terminal agent loops, not just isolated code generation.
Reasoning and vision
Near-expert graduate reasoning and much stronger vision
GPQA Diamond tests graduate-level multidisciplinary reasoning; CharXiv Reasoning evaluates chart and visual QA, with tools lifting it further.
GPQA Diamond with tools hits 94.2%, near expert-level graduate reasoning, and Humanity's Last Exam reaches 54.7% with tools (46.9% without). Visual understanding is the most visible upgrade: CharXiv Reasoning climbs to 91.0% with tools, up from Opus 4.6's 84.7%, which makes the model far more reliable for chart reading, OCR, and screenshot reasoning.
Tool-augmented agents
Leads on computer use, finance agents, and scaled tool calls
OSWorld-Verified covers long desktop and browser workflows; Finance Agent v1.1 and MCP-Atlas measure real tool orchestration.
Opus 4.7 leads its comparison set on computer use (OSWorld-Verified 78.0%), financial analysis (Finance Agent v1.1 64.4%), and scaled tool calling (MCP-Atlas 77.3%). The one place Opus 4.6 still edges it is BrowseComp agentic search (83.7% vs 79.3%), so for pure open-web retrieval the gap with 4.6 is small — everywhere else 4.7 is the safer default.
When to use it
- Complex software engineering: cross-file refactors, test diagnosis, and multi-step PR repair where the SWE-bench lead translates into fewer failed iterations.
- Vision and multimodal analysis: chart reading, document OCR, screenshot reasoning, and UI work — the largest single jump over 4.6.
- Enterprise knowledge work: reports, contracts, research reviews, and finance workflows with tool access.
- Long-horizon agents: MCP and computer-use workflows that can run for hours.
Opus 4.7 vs its siblings
Pick Opus 4.7 over Sonnet 4.6 when accuracy on the hardest tasks matters more than latency or unit cost; Sonnet stays the better default for high-volume online traffic. Move up to Opus 4.8 when you need its honesty/uncertainty improvements and independent Effort Control; 4.7 remains a strong, lower-variance choice for established pipelines.
CrossModel exposes Claude Opus 4.7 through Anthropic-compatible /v1/messages and OpenAI-compatible /v1/chat/completions. Current pricing is available in the model catalog.