
Overview
Claude Opus 4.6 is Anthropic's flagship model released on February 5, 2026. It was the first generally available Opus-class model with a 1M-token context window, and it moved the family forward in knowledge work, long-context retrieval, agentic coding, and computational biology.
Compared with Opus 4.5, the jump is especially visible on knowledge-work ELO and on long-context retrieval, where MRCR v2 rises from 18.5% to 76%. Opus 4.6 supports both Extended Thinking and Adaptive Thinking (low / medium / high / xhigh), making it well suited to knowledge-intensive agents, long-document synthesis, and research workflows that need controlled reasoning depth.
Key capabilities
| Dimension | Detail |
|---|---|
| Context window | 1,000,000 tokens |
| Max output | 131,072 tokens |
| Input modalities | Text, image |
| Output modalities | Text |
| Tools | function calling, structured outputs, streaming, computer use, MCP |
| Reasoning | Extended Thinking + Adaptive Thinking (low / medium / high / xhigh) |
Prompt caching uses product-level multipliers: cache reads are 0.1x the base input rate, 5-minute writes are 1.25x, and 1-hour writes are 2x. See live pricing in the model catalog.
Benchmarks
Opus 4.6's strengths cluster around agentic coding, long-context retrieval, and knowledge-heavy reasoning. Each was a clear step up from Opus 4.5 at release.
Agentic coding: Terminal-Bench 2.0
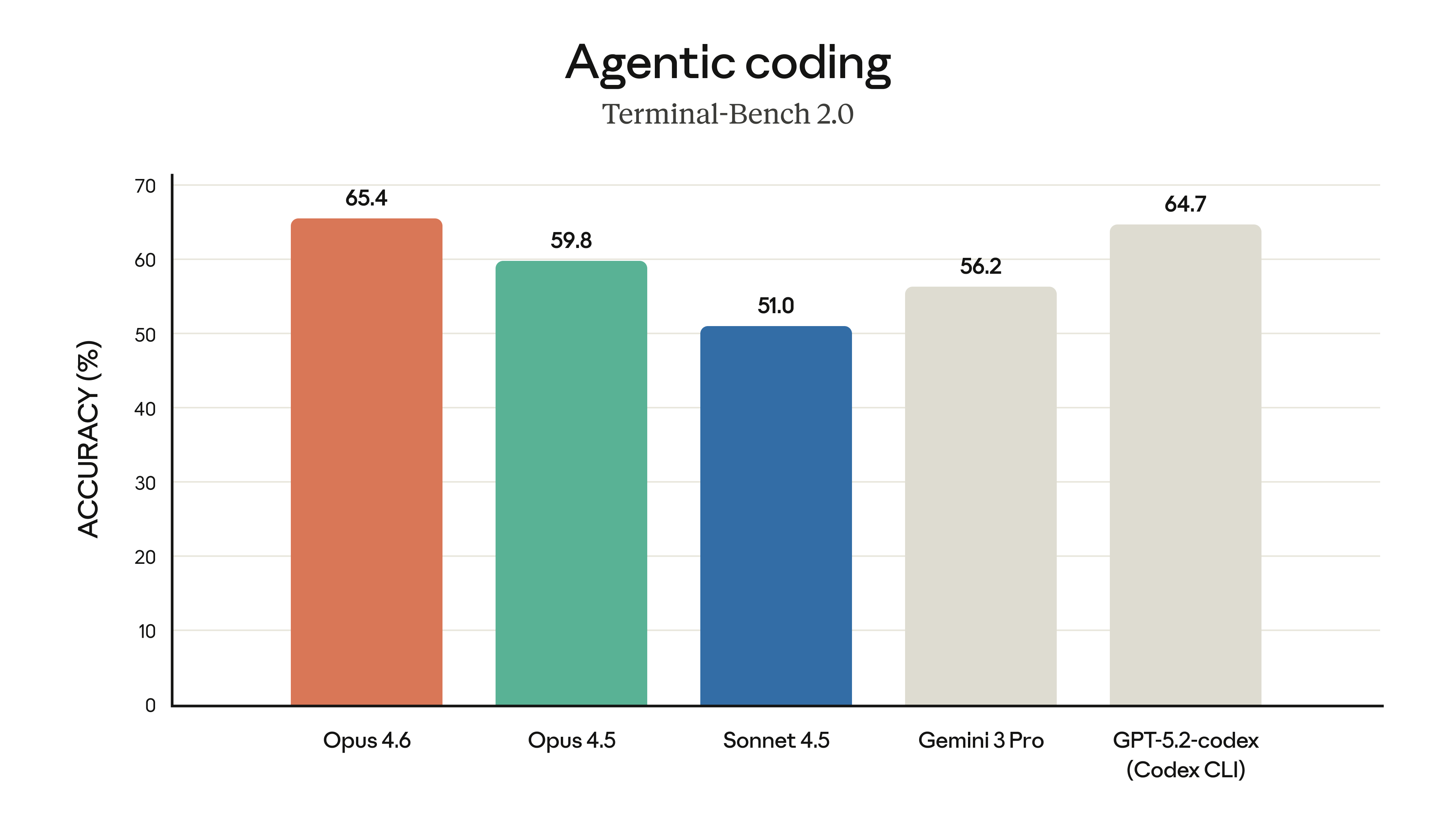
Opus 4.6 scores 65.4% on Terminal-Bench 2.0, ahead of Opus 4.5 (59.8%), Gemini 3 Pro (56.2%), and GPT-5.2-codex (64.7%). The benchmark matters because it exercises real terminal workflows — reading state, running tests, and iterating — rather than isolated code generation.
Long context and retrieval
A 1M context window paired with a generational jump in retrieval
MRCR v2 measures multi-needle recall over long context, jumping from Opus 4.5's 18.5% to 76%; BrowseComp covers hard information retrieval.
The headline upgrade is reliability across the full 1M-token window. MRCR v2 multi-needle recall jumps from Opus 4.5's 18.5% to 76%, so the larger context is genuinely usable — you can drop an entire spec or codebase in and still recover the right facts. On BrowseComp, Opus 4.6 posts 84.0%, among the strongest hard-retrieval results at release.
Knowledge work and reasoning
Leading knowledge-work ELO and multidisciplinary reasoning at release
GDPval-AA covers deliverable-heavy work such as reports, contracts, and research synthesis; GPQA Diamond and HLE measure graduate-level reasoning.
Opus 4.6 reaches 1606 ELO on GDPval-AA, leading the knowledge-work comparison at release, with 91.3% on GPQA Diamond and 60.1% on Finance Agent v1.1. Anthropic also highlights roughly 2x the Opus 4.5 result on its computational biology examples.
When to use it
- Deep knowledge work: reports, legal documents, academic reviews, and long-form analysis.
- Long-document analysis: a 1M context window plus much stronger MRCR v2 retrieval.
- Computational biology and research: roughly 2x Opus 4.5 on Anthropic's computational biology examples.
- Complex agents: parallel tool execution and agent teams for multi-step workflows.
Opus 4.6 vs newer Opus
Opus 4.6 remains a solid choice for established knowledge-work and long-context pipelines. Step up to Opus 4.7 for higher SWE-bench coding accuracy and much stronger vision, or Opus 4.8 for its honesty improvements and independent Effort Control.
CrossModel exposes Claude Opus 4.6 through Anthropic-compatible /v1/messages and OpenAI-compatible /v1/chat/completions. Current pricing is available in the model catalog.